Cultivating Software Quality Improvement in the Classroom: An Experience with ChatGPT
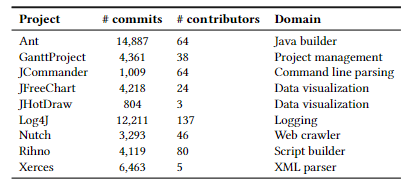
Large Language Models (LLMs), like ChatGPT, have gained widespread popularity and usage in various software engineering tasks, including programming, testing, code review, and program comprehension. However, their effectiveness in improving software quality in the classroom remains uncertain. In this paper, we aim to shed light on our experience in teaching the use of ChatGPT to cultivate a bugfix culture and leverage LLMs to improve software quality in educational settings. This paper discusses the results of an experiment involving 102 submissions that carried out a code review activity of 1,230 rules. Our quantitative and qualitative analysis reveals that a set of PMD quality issues influences the acceptance or rejection of the issues, and design-related categories that take longer to resolve. While students acknowledge the potential of using ChatGPT during code review, some skepticism persists. Code review can become a vital part of the educational computing plan through this experiment. We envision our findings to enable educators to support students with code review strategies to raise students' awareness about LLM and promote software quality in education.
If you are interested to learn more about the process we followed, please refer to our paper.
Our recorded tutorial: How to use ChatGPT?
Our recorded tutorial: How to use PMD?